突然のTwitter砲にもなんとか耐えたさくらVPSに感謝する
なんか、2/6 の夜に「修士論文の代わりに退学願を提出してきた」が Twitter でばずったらしく、Yahoo 砲よろしく突如としてアクセスが集中しました。下の方にリソースモニタリングのグラフを貼りつけてますが、今までがほぼ 0 に見えてしまうくらいに来てたのでびっくりでした。
まぁ色々コメントつけて頂いたりしてますが、もう2 年も前なんでこのエントリについて今更僕から突っ込むことは無くて、あのエントリはあのエントリとして見て頂ければと思います。ここでは今回そんな突然のアクセス集中にも見事耐えてくれたさくら VPS に感謝しつつ、アクセス集中の状況を鯖管的立場から分析してみましょう。
ちなみに、以前エントリに書いていますがサーバの構成としてはさくら VPS1 台で、CentOS+Apache+mod_fastcgi+PHP-FPM+MySQL5.5(InnoDB)で WordPress を動かしています。
ページはちゃんと返せていたのか?
アクセスが集中すると、エラーページを返してしまう可能性があります。エラーの原因は色々あるでしょうが、500 番台のステータスコードが返っているか確認することでざっと見ることはできます。(そもそも Apache がちゃんと動いていなければアクセスログすら残らないですが今回それは大丈夫だったようです)
別に記録しているグラフで見ると、「2/6 の 22:00 過ぎ」に http の通信が返ってこないことがあったみたいでしたのでこの時間帯を調べてみましょう。
アクセスログを less とかで開いてざっと目視で確認(俗に言う「目 grep」)してもいいですが、仕事とかではきちんと数値で出す必要がありますよね。そういう時、僕はコマンドの組み合わせでさっと集計することが多いので、今回それをご紹介。
アクセスログはいわゆる Apache 標準の combined の最後に処理マイクロ秒(%D)を追加したものだとします。
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %D" combined
tail -3 access_log.20110206
192.168.1.1 - - [06/Feb/2011:23:59:57 +0900] "GET /2009/03/02/185833 HTTP/1.0" 200 34092 "-" "Mozilla/4.0 (..." 1199490
192.168.1.2 - - [06/Feb/2011:23:59:57 +0900] "GET /2009/02/27/120733 HTTP/1.1" 200 77154 "-" "Mozilla/5.0 (..." 1065235
192.168.1.3 - - [06/Feb/2011:23:59:57 +0900] "GET /2009/02/27/120733 HTTP/1.0" 200 40960 "-" "-" 1097226awk入門
まず集計したいのは「2/6 の 22:00 過ぎ」に「500 番が返っていたか」です。とりあえず見るならこんな感じ。うーん。出てますね。
grep "2011:22:" access_log.20110206 | awk '$9==500{print}'
192.168.1.1 - - [06/Feb/2011:22:00:37 +0900] "GET /2009/02/27/120733 HTTP/1.1" 500 534 "-" "Mozilla/5.0 (..." 30000774
192.168.1.2 - - [06/Feb/2011:22:00:37 +0900] "GET /2009/02/27/120733 HTTP/1.1" 500 534 "-" "Mozilla/5.0 (..." 29999308
192.168.1.3 - - [06/Feb/2011:22:00:40 +0900] "GET /2009/02/27/120733 HTTP/1.1" 500 534 "http://twitter.com/" "Mozilla/5.0 (..." 29999068awk はログの分析の時には必須のスクリプト言語です。後ほどもうちょっと込み入った使い方を紹介しますが、とりあえずここでは、「9 カラム目が 500 だったら出力する」というのを毎行実行したと思って下さい。9 カラム目というのはログを head で眺めてみて、空白とかタブで区切られた数を数えてステータスコードに相当する所を数えた結果です(上のログ参照)。
最強のcut | sort | uniq -cを使う
500 番がどういう時間帯で出ていたのかを見てみましょう。awk で書いてもいいんですがワンライナーにはちょっと長いので、もっとお手軽にできる最強の組み合わせを使いましょう。
awk '$9==500{print}' blog_access_log.20110206 | cut -f2,3 -d: | sort | uniq -c
1 19:46
1 20:50
1 20:57
1 21:54
1 21:55
*** 22:00
*** 22:01
*** 22:02
*** 22:03
*** 22:04
*** 22:05
*** 22:06
*** 22:07
** 22:08
** 22:09
1 23:11
1 23:41それぞれの意味は自分で調べるのが一番ですが簡単に書くと、まずcutで「HH::mm」の部分を「:」を区切り文字に抜き出しています。そのあとsortで並べ替えて同じ時刻が連続並ぶ様にしておいて、uniq -cで集計しています。sortするのはログのタイムスタンプが前後してしまっている場合もあるからですね。というわけで、一応数は伏せてますが 22:00〜22:09 に集中して出ているようです。
ちなみにこのawk or cut | sort | uniq -cは本当に強力で、例えばアクセスログからアクセス上位の IP アドレスを集計したければこういう風にやるだけで簡単にできます。不正アクセスとかあったときにご活用くださいw
awk '{print $1}' access_log | sort | uniq -c | sort -n | tail -5
*** 192.168.1.1
*** 10.1.1.1
*** 192.168.1.3
*** 172.16.1.1
*** 192.168.1.2500 の原因を探る
さて Apache で 500 が出るパターンというのはサーバ側の問題なので、エラーログにも何かしら情報があることが多いです。
grep " 22:0" error_log
[Sun Feb 06 22:01:07 2011] [error] [client 192.168.1.1] FastCGI: comm with server "/etc/httpd/fcgi-bin/php-cgi" aborted: idle timeout (30 sec)
[Sun Feb 06 22:01:07 2011] [error] [client 192.168.1.1] FastCGI: incomplete headers (0 bytes) received from server "/etc/httpd/fcgi-bin/php-cgi"
[Sun Feb 06 22:01:07 2011] [error] [client 192.168.1.2] FastCGI: comm with server "/etc/httpd/fcgi-bin/php-cgi" aborted: idle timeout (30 sec)出てますね。サーバの構成は紹介したエントリの通り Apache が mod_fastcgi 経由で TCP のソケットを使って PHP-FPM デーモンと喋っているのですが、どうやらそこで timeout してしまっているようです。つまり、PHP 側がうまくしゃべれなくて、30 秒待って Apache 側で timeout した結果、ユーザにはサーバ側のエラーということで 500 番が返ってしまっていました様です。
その原因はちょっとわかんないですがその当時のグラフは以下の様な感じなのでそもそも CPU が 90%とかいってたみたいですので色々おかしなことは起こっててもおかしくないでしょうね。
awk入門その 2
影響がどの程度だったのかをみておきたいので、500 番はどの位でていたのかを 200 番と比較してみましょう。これも awk が大活躍です。
grep "2011:22:0" access_log.20110206 | awk '$9==200{ok++}$9==500{ng++}END{print ng/(ok+ng)*100}'
38.9419{}の前が if 文みたいなもので、9 番目のカラムが 200 だったらokという変数をインクリメント、500 だったらngをインクリメントしておきます。END{...}と書くと全行評価したあとに実行されるものを定義できるので、そこで割合をパーセントで計算して出力。
該当時間には 39%位が 500 番になってしまっていたようです。誠に申し訳ない><でもまぁこんなことはそうは起こらないのでとりあえず対応は無しとします。仕事じゃないしね!キリッ
リソースモニタリングしてた
さてもったいぶりましたが、さくらの VPS にはCloudForecast入れてリソースを可視化していたのでそちらをお見せします。 左上がトラフィック、その下が CPU 使用率、ロードアベレージ、右上が Apache の status、その下がメモリ使用量になります。kazeburo++
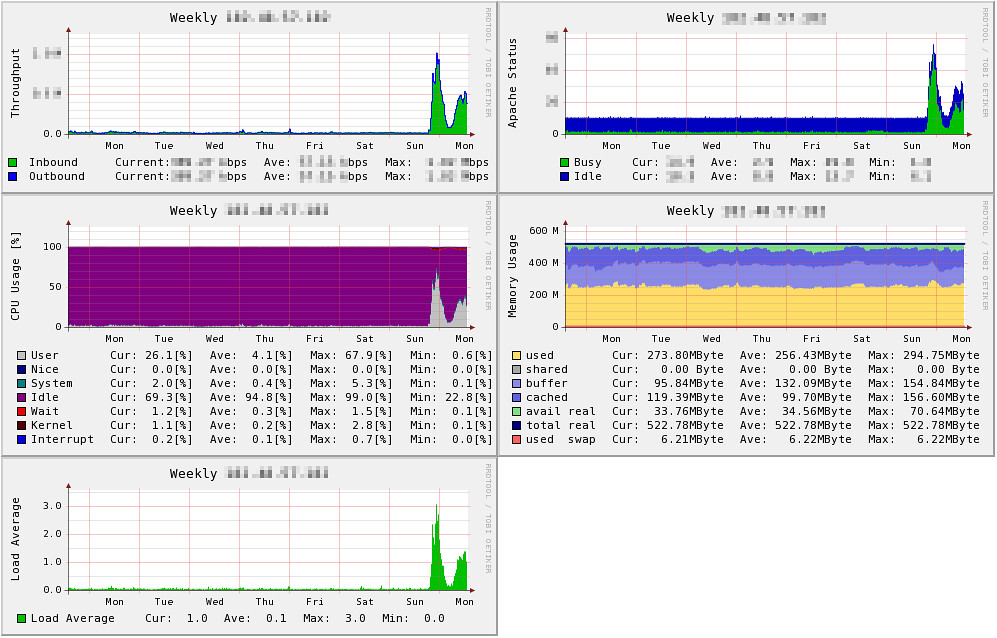
一見して分かる通り、2/6 おかしいw iowait も結構でてしまっていたのは、トラフィック出てるところを考えるとおそらく画像とかなぁ。そのせいで PHP も割を食ってた気はするので、S3 とかに置いてしまう手も検討中です。
ちなみに注目して頂きたいのはメモリのグラフです(右下)。メモリを食うのは主に PHP-FPM のプロセスなんですが、さくら VPS は 512MB とかなり小さいため、負荷に応じてこのプロセス数を調整したりすると swap してしまうのが怖いです。なので、プロセスの数は 3 つに固定にしてしまっています。そのため、httpd のプロセスの数(右上)はアクセス数に応じて増減していますが、メモリの使用量はほぼ一定になっています。swap してしまうとディスク IO は相当性能悪いみたいで、大抵はサーバを再起動しないといけなくなるので、そうなるよりは多少 500 番を返してしまってもプロセス数を制限しておいた方がいいですよ、という好例になりました。
そういえばレスポンスタイムってどんな感じ?awk入門その 3
さて、そういえば combined のアクセスログに処理時間を入れてる話はしましたが、実際どの位で返せているのか気になりました。ではまずは平均から。
grep "2011:21:" access_log.20110206 | awk '$9==200{l++;sum+=$NF/1000000}END{print sum/l}'
1.78198
grep "2011:22:0" access_log.20110206 | awk '$9==200{l++;sum+=$NF/1000000}END{print sum/l}'
20.7464
grep "2011:23:" access_log.20110206 | awk '$9==200{l++;sum+=$NF/1000000}END{print sum/l}'
2.08723
grep "2011:22:" access_log.20110205 | awk '$9==200{l++;sum+=$NF/1000000}END{print sum/l}'
0.74092$NFというのは各行の最終カラムを意味しています。lに 200 の件数、sumにレスポンス時間を秒単位で足し算していって、最後に割り算して平均をだしています。
昨日までは平均 1 秒もかかっていなかったのに、昨日から 2 秒位になってしまった。。。そして問題のあった 22:00〜22:09 だと 20 秒とかになってますね。これはひどい。
ただ、平均というやつは異常値に引きずられやすいのでもしかしたらこれはものすごい遅いものが引っ張っているだけなのではないか?というわけで、次に 95 パーセンタイル(全体の 95%が収まっている値)を出してみたいと思います。さっき書いたけどこれも awk(実際は asort 関数のある gawk)だったら手書きできる程度で一発です。
grep "2011:21" access_log.20110206 | awk '$9==200{l++;data[l]=$NF/1000000}END{pct=int(l*0.95);asort(data);print data[pct]'}
6.47321
grep "2011:22:0" access_log.20110206 | awk '$9==200{l++;data[l]=$NF/1000000}END{pct=int(l*0.95);asort(data);print data[pct]'}
30.016
grep "2011:23" access_log.20110206 | awk '$9==200{l++;data[l]=$NF/1000000}END{pct=int(l*0.95);asort(data);print data[pct]'}
6.72018
grep "2011:22" access_log.20110205 | awk '$9==200{l++;data[l]=$NF/1000000}END{pct=int(l*0.95);asort(data);print data[pct]'}
1.21503パーセンタイルを計算するには全行を評価した後に、並び替えて、小さい方から 95%番目に当たるものを表示すればいいだけです。END{...}の部分がまさにそのまんまですね。data[l]という形で各行の秒数を入れておいて、asort 関数で並び替え。lの 95%を整数にしておいて、その番号を指定してdataを表示してるだけです。gawk が使えない環境だと sort をやるには自前で書く必要があるので、その場合は一発でやるのはちょっと面倒そう。
で、、、結果としてはむしろ沢山ある小さい方の値が平均値を引き下げてくれていたようですね。。。だったら、ちょっと分布を見てみたい!というときには今度はcut | sort | uniq -cが役にたちます。ここではとりあえず 2/6 の 23:00 台。22:00 の様なアクセス集中は収まっていますがどんな感じだったのかな。
grep "2011:23:" access_log.20110206 | awk '$9==200{print $NF/1000000}' | cut -f1 -d. | sort -n | uniq -c
**** 0
**** 1
*** 2
*** 3
*** 4
*** 5
...$NF/1000000で小数点付きの秒単位になるので、小数点でcutしてます(awk で int にキャストすればいいだけじゃんというのは言わないで><)。あとはsort -nで数値として評価して並び替えてuniq -cで集計すればヒストグラムの完成。
うーむ。。。なんか普通に数秒かかってるのもあるのね。。。こうなったらどの秒が何パーセンタイルなのかも出してやる!
grep "2011:23:" access_log.20110206 | awk '$9==200{print int($NF/1000000)}' | sort -n | uniq -c | awk '{sum+=$1;data[NR]=$1;s[NR]=$2}END{for(i=1;i<=NR;i++){tmp+=data[i]; print s[i], tmp/sum*100}}'
0 47.2555
1 71.1387
2 80.9197
3 87.1387
4 91.0511
5 93.6788
6 95.4307
...さっきの結果をまた awk に食わせて計算してます。説明は割愛。これくらいが限度だな。。。
うーむ。。。結構遅いね。50%以上が 1 秒超えてる。。。2/5 まではどうだったのかな。
grep "2011:23:" access_log.20110205 | awk '$9==200{print int($NF/1000000)}' | sort -n | uniq -c | awk '{sum+=$1;data[NR]=$1;s[NR]=$2}END{for(i=1;i<=NR;i++){tmp+=data[i]; print s[i], tmp/sum*100}}'
0 85.4701
1 97.4359
2 99.1453
...Σ(゚ д ゚ lll)ガーン。。。かなり劣化してる様です。まぁアクセス数自体が増えてるのでしょうがないですね。単体でチューニングしてもいいんですが、まぁ一過性のものでしょうしとりあえず様子見。もしこれが続くようであれば、負荷分散してついでに可用性も上げておきたいので複数台運用したいところです。
いじょ。
というわけで、この程度の統計分析(と呼ぶのもおこがましいですが><)であれば、コマンドラインのワンライナーで十分に分析できます。
いや、こんなの perl で書いて使い回せばいいじゃん、とかいう意見もあると思うのですが、例えば複数サーバ運用してるとスクリプトを各サーバに置くのは面倒(更新したら配布しなきゃいけないし)だったりします。あとは、どの様な計算を行ったかがワンライナーに全て書かれているため、レポートするときにもコマンドを一緒に貼りつければそれがミスってないかどうかだれでも検証できます。そして、それを見た他の人が試してみたり改変したい時もコピペするだけなので便利です。
現場でトラブルシューティングするときなども、僕は上記の様なコマンドを駆使しています。よほど複雑な分析とかグラフを使って可視化したいとかがなければ、Excel などを使う必要はなくて、というか Excel なんか起動するのは待ってられないので、こんな感じで手元でやれるとスピードアップ間違いなしですね!
-
ibushi 11-02-08 (火) 13:31
はてブから参りまして、興味深く拝読しました。
ところで、わたしのところでは、複数サーバーでのスクリプト共有を git+ssh(もしくは Subversion+ssh)で実現してます。
そうはいってもワンライナーで片付けることの方が多いんですが。 -
ミクモちゃん 11-02-08 (火) 14:58
アクセス数とか具体的な数値があったらかなり参考になる記事でしたね。
あと、apache じゃなくて nginx ならどうなっていたかも気になります。 -
riywo 11-02-08 (火) 15:56
> ibushi さん
バージョン管理使うのは手ですね。全く別のシステム間で同期させるのはやはり面倒そうですがw>ミクモちゃん さん
アクセス数は意図して消してます。一応規模感は秘密ということで。集中時の問題は PHP-FPM が CPU 使い切ったことかなーと思ってるので web サーバを nginx にしても大して変化ないと思ってます。mod_cache などでキャッシュさせてなるべく PHP を通らない様にしようかと検討しているところです。
-
hhungry 11-02-08 (火) 16:20
画像のポップアップかっこいいですね。
ブラウザは Chrome を使っているのですが、Close ボタンが効かず
画像を閉じるのに少し戸惑いました。
IE,Firefox ではちゃんと Close ボタンが使えたので Chrome のバグですね。 -
riywo 11-02-08 (火) 18:35
> hhungry さん
おぉ確かに Chrome だとボタン効かないですね。Lightbox はいつも画像以外の場所をクリックして閉じてるので気づきませんでした。時間ある時にバグ情報とか漁ってみます。ありがとうございます!